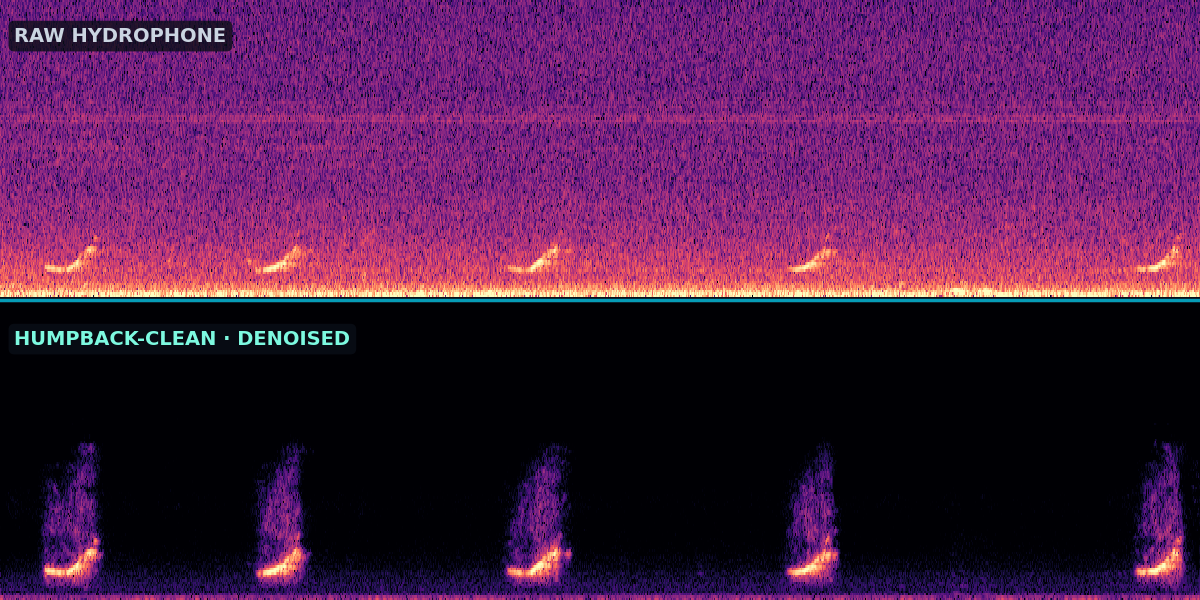
Most of the ocean's recorded song is buried. Hydrophones pick up vessel engines, water flow, broadband hiss, the hum of the deep sea — and somewhere underneath, a whale. We built a small neural network — Humpback-CLEAN — that learns what humpback song looks like and lifts it back out of that noise. Below are before/after recordings from hydrophones around the world. Press play, then switch between the original and the denoised version.
What it does
The denoiser takes a noisy recording and returns the same recording with the background suppressed and the signal preserved. Across the selected examples below it removes ~9–32 dB of background noise while keeping the song level essentially unchanged — these cases are chosen to illustrate the effect, and how much it helps depends on how much noise is present and how clear the underlying song is. The result is a clearer recording: calls that were smeared into the noise floor become legible to the eye and the ear, which makes them easier to detect, classify, and study.
How it works
Listen in the spectrogram
The audio is turned into a log-magnitude spectrogram (a 512-point STFT) — a picture of energy across frequency and time, the same view you see below.
Predict a mask
A small U-Net looks at that picture and predicts, for every time-frequency cell, how much of it is signal versus noise — a soft mask between keep and suppress.
Reconstruct
The mask is applied and the audio is rebuilt using the original phase — noisy cells turned down, faint real ones brought up — leaving a cleaner version of the same recording.
How we trained it
A denoiser is only as good as the clean examples it learns from. Ours learns from a curated, multi-dialect corpus of clean humpback song — recordings vetted by eye and ear for a high signal-to-floor ratio — which we then mix synthetically with a library of real ocean noise — vessel and engine noise, water flow, broadband hiss, the low-frequency hum of the deep sea — so the model sees the same song under many different kinds of noise and learns to undo it.
Two choices mattered most. First, diversity over volume: a smaller, cleaner, more geographically varied set beat a larger but redundant one — humpback song is regional, almost like a dialect, so coverage matters more than count. Second, when we added a noisier new population (Japan/Ogasawara song) we used it synthetic-only — its song became a clean target mixed with generic noise, never a noisy input/output pair — which folded in new song morphology without teaching the model to over-suppress the signal. Training the wrong way made earlier versions too aggressive; this version removes more background while leaving the song intact, which we verified by eye and ear, not by a single number.
See & hear it
Eight recordings, ordered from the cleanest to the hardest: a Hawaiian breeding ground, the Arctic waters of Disko Bay in West Greenland, two 1960s archival tapes, a lone singer off Hawaii, and then the deep-sea hum of Monterey Bay — where the song is all but buried and the denoiser has the most work to do. The two spectrograms are on the same color scale, so what you see disappearing really is noise being removed. Tap either panel to listen to that version and seek; use the toggle to switch which one you hear.
How it compares
We didn't build this in a vacuum. The strongest general-purpose tool for the job is the Earth Species Project's biodenoising model (Miron et al., ICASSP 2025) — one network trained to clean the calls of many species at once and, remarkably, trained without a single clean recording to learn from. It's excellent work, and we use it ourselves: it powers one of the steps in our Listen tab. But generality has a price. A model that has to keep birds, frogs, and dolphins all sounding right can't lean on what humpback song, specifically, looks like.
Humpback song is dense and continuous — long, overlapping phrases with almost no silence between them — and at full strength a general-purpose model, unsure how much of that wash is whale, suppresses too hard: it gates the quiet passages toward silence and strips away real song along with the noise. To protect the song, we run it gently — about a third of its output, blended back with the original — which spares the call but barely touches the noise, leaving the recording a little quieter and still hazy. Neither setting is enough for humpback song. That gap is exactly why we trained Humpback-CLEAN — to take out the background and keep the call.
One recording, three ways — Original, ESP biodenoise (its direct, full-strength output), and Humpback-CLEAN. Tap a panel to listen, and watch where each version holds the song and where it lets go.
ESP biodenoise: Miron et al., “Biodenoising: Animal Vocalization Denoising without Access to Clean Data,” ICASSP 2025 — arXiv:2410.03427. Shown at its 16 kHz default output; in our Listen tab we blend roughly 30% of it with the original.
What it can — and can't — do
- It cannot hallucinate. The output is the input times a bounded (0–2×) per-cell mask, so it only rescales energy that was recorded — a silent cell stays silent (0 × anything = 0). If there is no whale, nothing appears.
- It is tuned for humpback song. It generalizes surprisingly well to other tonal calls, but it was trained on humpback song and is most reliable there.
- It only removes background. The song's own level is left essentially unchanged (within ~2 dB across the examples here) — it lowers what surrounds the call, it doesn't reshape the call itself.
- It's an enhancement, not the whale's-ear truth. The mask is judged by what we can see and hear and by a detector score — human-and-machine salience, not a humpback's. A whale's hearing reaches past the band and the fine detail we optimize for, and a magnitude-only filter discards some of that. So we treat the denoised version as a lens for detection and listening, and always keep the original recording.